Achieving robust vision-based humanoid locomotion remains challenging due to two fundamental issues: the
sim-to-real gap introduces significant perception noise that degrades performance on fine-grained tasks,
and training a unified policy across diverse terrains is hindered by conflicting learning objectives. To
address these challenges, we present an end-to-end framework for vision-driven humanoid locomotion.
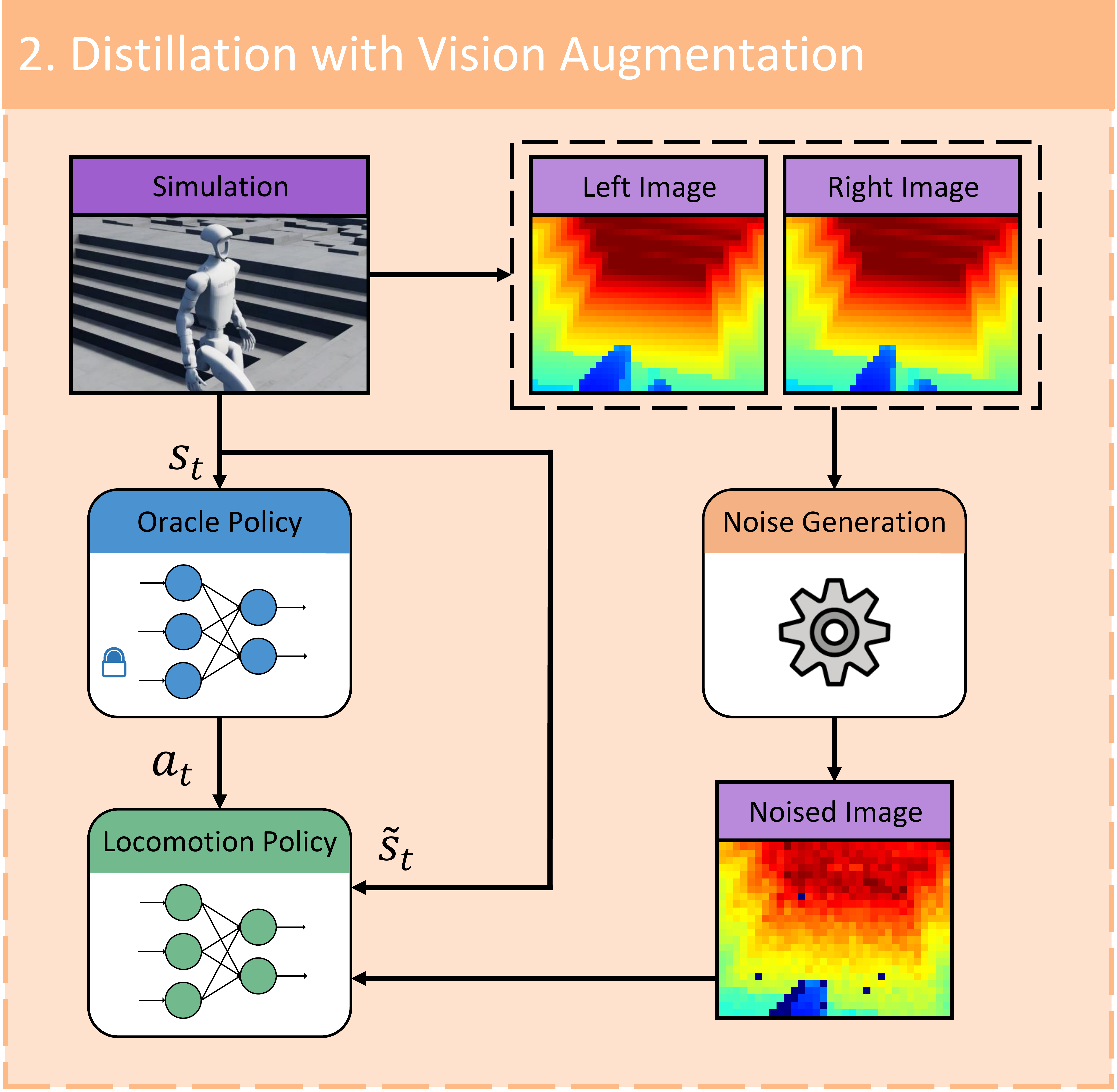
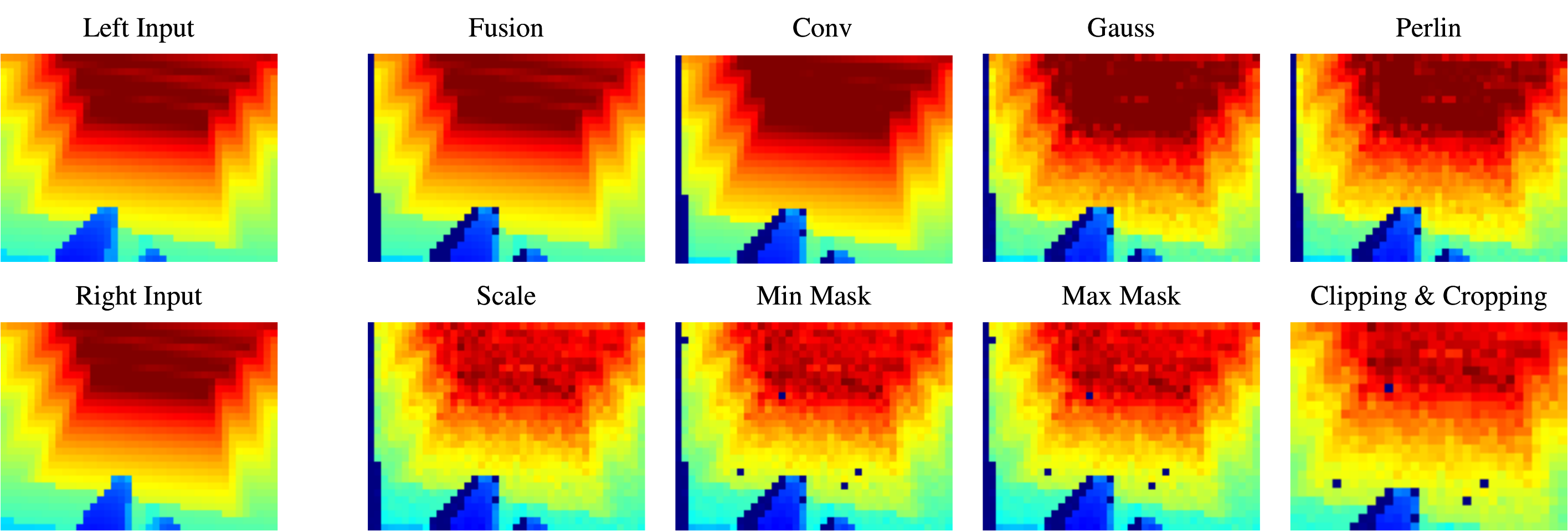
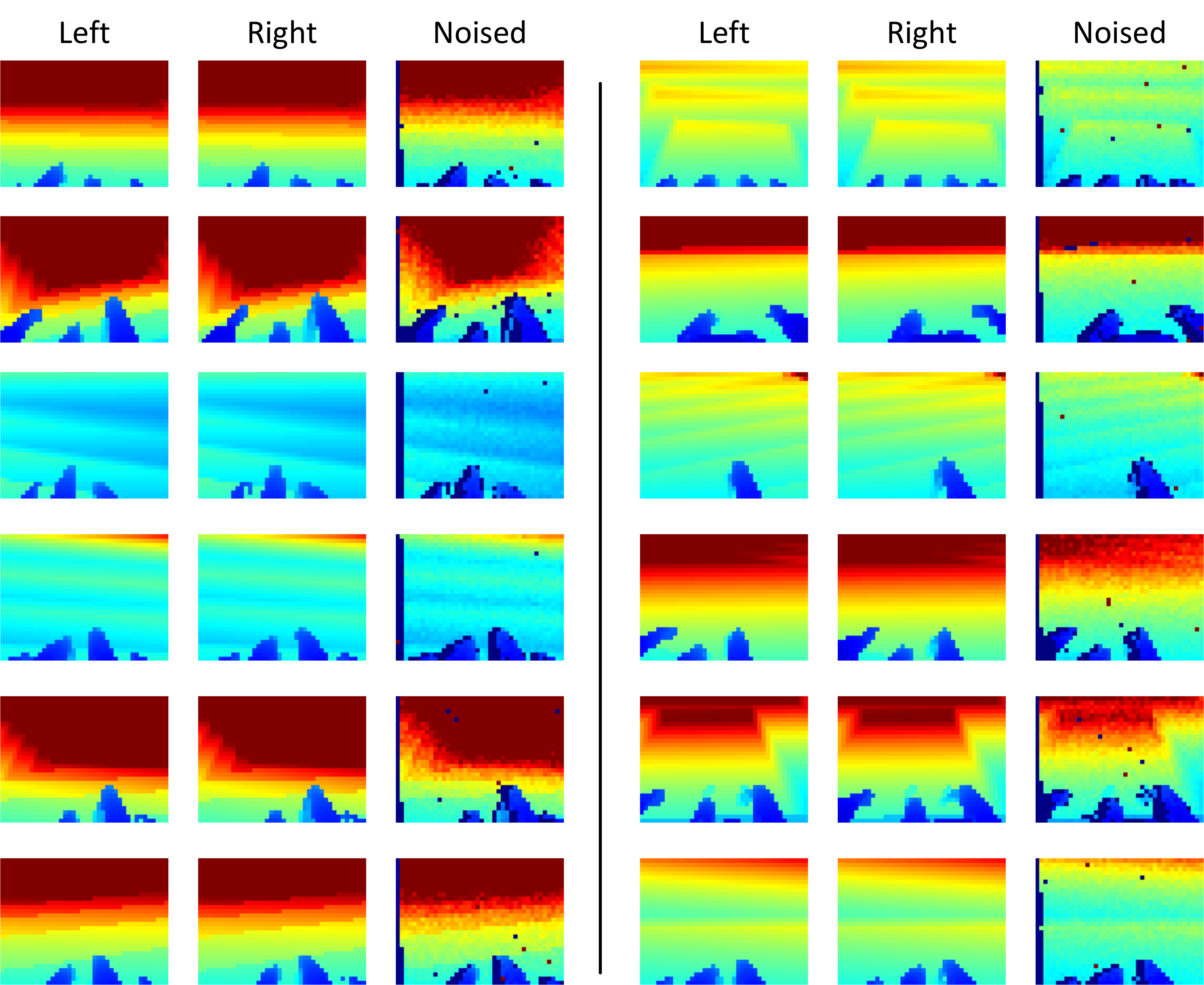
For robust sim-to-real transfer, we develop a high-fidelity depth sensor simulation that captures stereo
matching artifacts and calibration uncertainties inherent in real-world sensing. We further propose a
vision-aware behavior distillation approach that combines latent space alignment with noise-invariant
auxiliary tasks, enabling effective knowledge transfer from privileged height maps to noisy depth
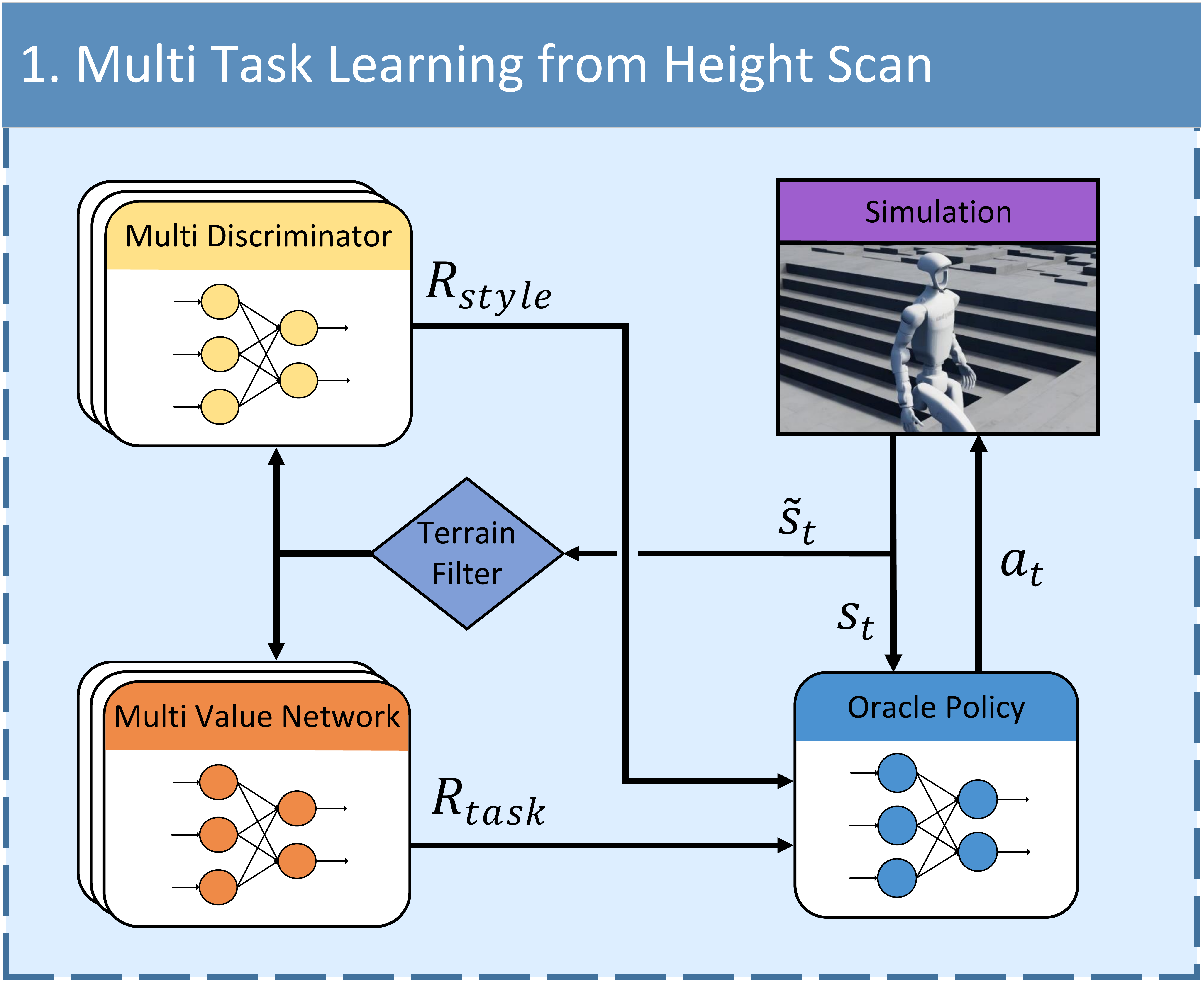
observations. For versatile terrain adaptation, we introduce terrain-specific reward shaping integrated
with
multi-critic and multi-discriminator learning, where dedicated networks capture the distinct dynamics and
motion priors of each terrain type.
We validate our approach on two humanoid platforms equipped with different stereo depth cameras. The
resulting policy demonstrates robust performance across diverse environments, seamlessly handling extreme
challenges such as high platforms and wide gaps, as well as fine-grained tasks including bidirectional
long-term staircase traversal.